
The 2026 Handwriting Recognition Revolution
For decades, converting handwritten notes to text was a frustrating compromise. You could either accept the rigid constraints of a stylus-and-tablet app that forced you to write in a specific way, or you could snap a photo of your paper notebook and pray that a traditional OCR engine like Tesseract could decipher your scrawl. Neither path delivered reliable results for anything beyond neat, block-printed text.
That hierarchy has been upended in 2026. Frontier multimodal AI models — specifically GPT-5, Claude Opus 4.7, and Gemini 3 — now occupy the top three positions on the IAM Handwriting Database leaderboard, a benchmark of 13,353 text lines from 657 different writers. These general-purpose vision-language models (VLMs) have surpassed specialized handwriting text recognition (HTR) models and cloud APIs by a significant margin, achieving character error rates (CER) below 1.5%.
But the story is not as simple as a single leaderboard. Accuracy varies dramatically depending on writing style — the gap between neat print and messy cursive can cause a 20 to 30 percentage point drop even with the best models. And the right choice depends on whether you need raw transcription, structured output with bounding boxes, offline privacy, or cost efficiency at scale. This article breaks down the accuracy data, explains the metrics that matter, and provides implementation guidance for developers and enterprise buyers who need to make an informed architectural decision.
What CER and WER Actually Mean for Handwriting Accuracy
Before diving into the leaderboard, it is essential to understand the two metrics used throughout this article: Character Error Rate (CER) and Word Error Rate (WER). These are the standard evaluation metrics for handwriting recognition systems, and they are frequently confused or misrepresented.
CER measures the percentage of characters (letters, numbers, punctuation) that the system got wrong — including substitutions, insertions, and deletions — compared to the ground truth text. A CER of 1.22% means that out of every 10,000 characters, the model misrecognized roughly 122. WER applies the same logic at the word level. Because a single wrong character can make an entire word incorrect, WER is typically higher than CER.
| Metric | What It Measures | Lower Is | Typical Range for Good Handwriting OCR |
|---|---|---|---|
| CER | Character-level errors (substitutions, insertions, deletions) | Better | 1% – 5% |
| WER | Word-level errors | Better | 5% – 15% |
| Word Accuracy | Percentage of words correctly recognized (100% – WER) | Higher | 85% – 99% |
A critical nuance: CER and WER figures are only meaningful when compared against the same dataset. The IAM Handwriting Database, which underpins the CodeSOTA leaderboard cited in this article, contains a mix of writing styles from 657 writers. A model that achieves 1.22% CER on IAM may perform differently on a dataset of cursive-only historical documents or on a collection of hastily written meeting notes. Throughout this article, we note which dataset produced each figure so you can assess relevance to your own use case.
Accuracy Leaderboard: Ranked by CER on the IAM Handwriting Database
The following leaderboard ranks models by their reported CER on the IAM Handwriting Database, the most widely cited benchmark in academic and industry handwriting recognition research. The data comes from CodeSOTA's 2026 benchmark, which tested frontier VLMs, cloud APIs, specialized HTR models, and legacy OCR engines against the same 13,353-line dataset.
| Rank | Model / Service | Category | CER (%) | Notes |
|---|---|---|---|---|
| 1 | GPT-5 | Frontier VLM | ~1.22% | Current SOTA; general multimodal model |
| 2 | Claude Opus 4.7 | Frontier VLM | ~1.31% | General multimodal model |
| 3 | Gemini 3 | Frontier VLM | ~1.44% | General multimodal model |
| 4 | GPT-5-mini | Frontier VLM (cost-optimized) | ~1.52% | ~$2/1K pages; sweet spot for cost vs accuracy |
| 5 | Azure Document Intelligence v4.0 | Cloud API | ~1.8% | Best for structured output with bounding boxes |
| 6 | DTrOCR | Specialized HTR | ~2.38% | WACV 2024; leads specialized HTR category |
| 7 | TrOCR-Large | Specialized HTR | ~2.89% | Most practical open-weight baseline |
| 8 | ABBYY FineReader 16 | Desktop OCR | ~5-8% (estimated on IAM) | Full offline privacy; ~92-95% on good handwriting |
| 9 | Tesseract 5 | Legacy OCR | ~12.5% | Effectively unusable for handwriting |
Tier 1: Frontier VLMs (GPT-5, Claude Opus 4.7, Gemini 3)
The top tier of the leaderboard is occupied by general-purpose multimodal AI models — not specialized OCR tools. GPT-5 leads at approximately 1.22% CER, followed by Claude Opus 4.7 at 1.31% and Gemini 3 at 1.44%. These models were not designed for handwriting recognition; they are vision-language models trained on vast and diverse datasets that happen to include handwriting. Their ability to understand context, infer missing strokes, and correct ambiguous characters gives them a decisive advantage over models that rely purely on pixel-to-character mapping.
| Model | CER on IAM | Approximate Cost per 1K Pages | Best For |
|---|---|---|---|
| GPT-5 | ~1.22% | ~$5-8 (estimated) | Maximum accuracy; complex documents |
| Claude Opus 4.7 | ~1.31% | ~$5-8 (estimated) | Maximum accuracy; long-form documents |
| Gemini 3 | ~1.44% | ~$3-5 (estimated) | Maximum accuracy; Google Cloud ecosystem |
| GPT-5-mini | ~1.52% | ~$2 | Cost-sensitive bulk transcription |
The standout in this tier for practical applications is GPT-5-mini. At approximately 1.52% CER and roughly $2 per 1,000 pages, it offers the best accuracy-to-cost ratio in the entire leaderboard. For bulk transcription of handwritten documents where near-perfect accuracy is required but budget is a constraint, GPT-5-mini is the current sweet spot.
Tier 2: Cloud APIs (Azure, AWS Textract, Google Vision)
Cloud API services offer a middle ground between the raw accuracy of frontier VLMs and the simplicity of consumer apps. They provide structured output — typically including bounding boxes, confidence scores, and layout information — which makes them suitable for document processing pipelines where you need to know not just what was written, but where it was written on the page.
| Service | CER on IAM | WER on Cursive | Structured Output | Approximate Cost per 1K Pages |
|---|---|---|---|---|
| Azure Document Intelligence v4.0 | ~1.8% | ~8.67% WER (~91.3% word-level) | Yes (bounding boxes, layout) | ~$10 |
| Amazon Textract | Not reported on IAM | ~10.5% WER (~89.5% word-level) | Yes (bounding boxes, forms) | ~$15 |
| Google Cloud Vision | Not reported on IAM | ~37% WER (~63% on cursive) | Yes (bounding boxes) | ~$10 |
Azure Document Intelligence v4.0 is the clear leader in this tier. At approximately 1.8% CER on the IAM database and 91.3% word-level accuracy on cursive handwriting, it approaches frontier VLM territory while providing structured bounding-box output that makes it easier to integrate into enterprise document processing workflows. Its pricing of roughly $10 per 1,000 pages at small scale is competitive for business use cases.
Amazon Textract achieves approximately 89.5% word-level accuracy on cursive handwriting, according to a 2026 benchmark cited by Suparse. Google Cloud Vision lags significantly on cursive, with only about 63% accuracy — though it achieves 99.1% on printed text. Google's offering is best reserved for mixed documents where the handwriting component is minimal.
Tier 3: Specialized HTR (DTrOCR, TrOCR, Transkribus)
Specialized handwriting text recognition models were the state of the art before frontier VLMs arrived. DTrOCR, presented at WACV 2024, achieves 2.38% CER on the IAM database, making it the best-performing model in the specialized HTR category. TrOCR-Large, at 2.89% CER, remains the most practical open-weight baseline for developers who need to run inference on their own infrastructure.
| Model | CER on IAM | Open Weights | Best For |
|---|---|---|---|
| DTrOCR | ~2.38% | Yes | Historical documents; academic research |
| TrOCR-Large | ~2.89% | Yes | Practical open-weight baseline; fine-tuning |
| Transkribus | ~3-5% (estimated) | No (proprietary) | Historical document transcription; archival use |
While these models no longer hold the top positions on the leaderboard, they offer advantages that frontier VLMs and cloud APIs cannot match. DTrOCR and TrOCR can be run entirely offline on your own hardware, eliminating data privacy concerns. They are also more suitable for fine-tuning on specific document types — such as historical manuscripts, medical records, or specialized forms — where a general-purpose VLM might struggle with domain-specific vocabulary or layout conventions.
Transkribus, a proprietary platform designed for historical document transcription, occupies a niche that neither frontier VLMs nor cloud APIs serve well. Its accuracy on historical handwriting is competitive with general-purpose models, and it includes specialized features for diplomatic transcription and manuscript studies.
Tier 4: Desktop and Legacy OCR (ABBYY, Tesseract)
Desktop OCR and legacy OCR engines occupy the bottom of the accuracy leaderboard, but they remain relevant for specific use cases where offline operation, privacy, or cost are paramount.
| Tool | Handwriting Accuracy | Printed Text Accuracy | Offline | Best For |
|---|---|---|---|---|
| ABBYY FineReader 16 | ~92-95% on good handwriting; ~91.7% on cursive | ~99.8% | Yes | Desktop offline privacy; mixed documents |
| Tesseract 5 | ~12.5% CER on IAM; ~60-70% on print-style handwriting | ~95%+ on clean print | Yes | Printed text only; open-source projects |
ABBYY FineReader 16 achieves up to 95% accuracy on handwriting under good conditions — meaning clear, well-lit scans of neat handwriting on unlined paper. An independent test found it at 91.7% on cursive handwriting and 95.2% on handwritten print. For users who cannot send documents to a cloud API due to data privacy requirements, ABBYY remains the best offline option. Its printed text accuracy of 99.8% also makes it a strong choice for mixed documents that contain both printed and handwritten content.
Real-World Variance: Accuracy Drops from Neat Print to Messy Cursive
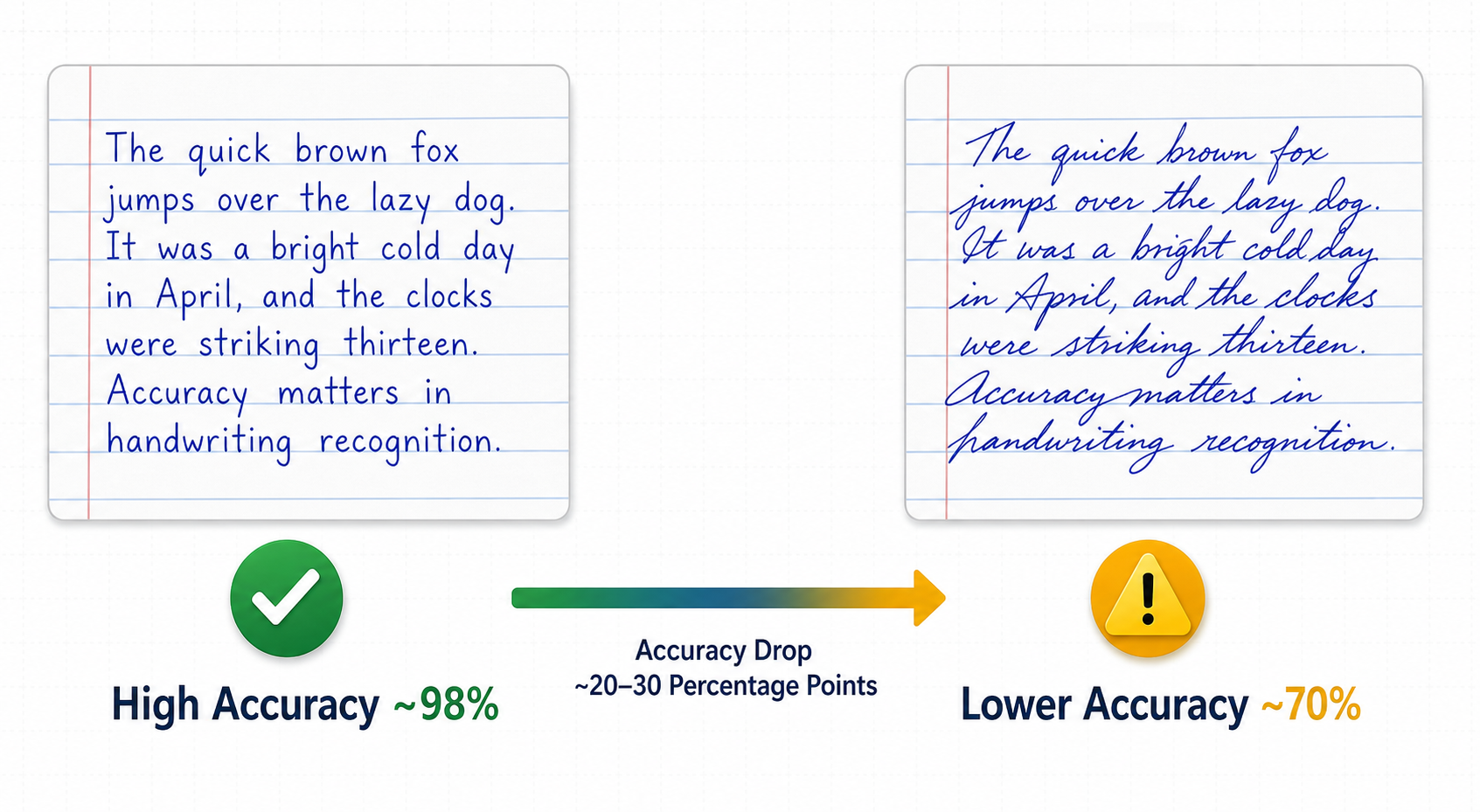
The leaderboard figures tell only part of the story. Real-world accuracy depends heavily on writing style, and the variance is dramatic. AIMultiple's cursive handwriting benchmark — 100 samples from 10 writers, preserving natural letter connectivity, stroke variability, spacing distortion, and line fluidity — found that GPT-5 achieved 95% accuracy on handwriting overall, while Gemini 2.5 Pro achieved 93%. But these are averages across the full dataset. When isolating cursive-only samples, the numbers tell a different story.
| Service | Accuracy on Neat Print | Accuracy on Cursive | Drop |
|---|---|---|---|
| GPT-5 | ~97-98% | ~90-92% | ~5-8 percentage points |
| Azure Document Intelligence | ~95-96% | ~91.3% word-level | ~4-5 percentage points |
| Amazon Textract | ~93-95% | ~89.5% word-level | ~3-6 percentage points |
| Google Cloud Vision | ~90-92% | ~63% | ~27-29 percentage points |
| Generic free OCR | ~70-80% | ~50-60% | ~20-30 percentage points |
The most striking drop is Google Cloud Vision's: from approximately 90-92% on neat print to just 63% on cursive — a drop of nearly 30 percentage points. Even the best models, like GPT-5 and Azure Document Intelligence, see a 4-8 percentage point drop when moving from neat print to cursive. For users who primarily write in cursive, this variance can mean the difference between a usable transcription and a frustrating experience.
When to Choose Each Tier: Accuracy vs Cost vs Bounding Boxes vs Privacy
The decision matrix below maps the four tiers against the key decision factors that matter for developers and enterprise buyers. No single solution wins across all dimensions.
| Decision Factor | Frontier VLMs | Cloud APIs | Specialized HTR | Desktop OCR (ABBYY) | Legacy OCR (Tesseract) |
|---|---|---|---|---|---|
| Accuracy (handwriting) | Best (~1.2-1.5% CER) | Good (~1.8-10.5% WER) | Good (~2.4-2.9% CER) | Fair (~5-8% CER) | Poor (~12.5% CER) |
| Cost per 1K pages | Moderate-High (~$2-8) | Moderate (~$10-15) | Low (self-hosted) | One-time license (~$200-500) | Free |
| Structured output (bounding boxes) | No (requires custom parsing) | Yes (native) | Varies | Yes (limited) | Yes (limited) |
| Offline / Privacy | No (API only) | No (API only) | Yes (self-hosted) | Yes (desktop) | Yes (self-hosted) |
| Integration complexity | High (prompt engineering, parsing) | Medium (API calls, output parsing) | Medium-High (model deployment) | Low (desktop app) | Low (library) |
| Best for | Maximum accuracy; complex documents | Document processing pipelines | Historical documents; offline use | Desktop offline privacy | Printed text only |
Implementation Code Samples for API Calls
The following code samples demonstrate how to call the top-tier APIs for handwriting recognition. These are minimal examples focused on the key parameters — image input, prompt engineering for VLMs, and language hints for cloud APIs.
GPT-5 Multimodal API (Python)
import openai
client = openai.OpenAI()
response = client.chat.completions.create(
model="gpt-5",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Transcribe the handwritten text in this image exactly as written. Return only the transcribed text, no explanations."
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,{base64_encoded_image}"
}
}
]
}
],
max_tokens=4096
)
transcription = response.choices[0].message.content
print(transcription)Azure Document Intelligence v4.0 (Python)
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.core.credentials import AzureKeyCredential
endpoint = "YOUR_AZURE_ENDPOINT"
key = "YOUR_AZURE_KEY"
client = DocumentIntelligenceClient(
endpoint=endpoint,
credential=AzureKeyCredential(key)
)
with open("handwritten_note.jpg", "rb") as f:
poller = client.begin_analyze_document(
model_id="prebuilt-read",
body=f,
content_type="image/jpeg"
)
result = poller.result()
for page in result.pages:
for line in page.lines:
print(f"Text: {line.content}")
print(f"Bounding box: {line.polygon}")
print(f"Confidence: {line.confidence}")TrOCR Inference (Hugging Face Transformers)
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
processor = TrOCRProcessor.from_pretrained("microsoft/trocr-large-handwritten")
model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-large-handwritten")
image = Image.open("handwritten_note.jpg").convert("RGB")
pixel_values = processor(images=image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(transcription)Recommendations by Use Case
The right handwriting recognition solution depends on your specific requirements. The following recommendations map the accuracy data and decision factors from this article to common use cases.
- Raw transcription at maximum accuracy: GPT-5-mini — At ~1.52% CER and ~$2 per 1,000 pages, it offers the best accuracy-to-cost ratio in the entire leaderboard. Use GPT-5 full model only when the absolute highest accuracy is required and cost is not a concern.
- Structured output with bounding boxes: Azure Document Intelligence v4.0 — At ~1.8% CER with native bounding box and layout output, it is the best choice for document processing pipelines where you need to know the position of each word on the page.
- Offline privacy: ABBYY FineReader 16 — At ~92-95% accuracy on good handwriting with full offline operation, it is the best option for users who cannot send documents to a cloud API due to data privacy requirements.
- Historical documents: DTrOCR or Transkribus — DTrOCR at 2.38% CER leads the specialized HTR category and can be fine-tuned on historical manuscripts. Transkribus offers specialized features for archival transcription.
- Printed text only: Tesseract 5 — If your documents contain only printed text, Tesseract is a free and effective solution. Do not use it for handwriting.