
The Pre-2026 PKM Model: You Tag, Link, and File — the System Stores
For the better part of a decade, building a personal knowledge management system meant becoming a full-time librarian of your own mind. You captured a highlight, assigned it three tags, filed it into a folder hierarchy, and maybe — if you had the discipline — manually linked it to a related note. The tool was a passive container. It stored what you gave it, searched by exact keyword, and waited for you to remember where you put things.
This model worked, but it carried a heavy cognitive tax. Every piece of information you saved required a decision about where it belonged and how it connected. The system never surfaced connections you hadn't explicitly built. It never noticed that three notes from different folders all touched on the same concept. It never synthesized. The burden of structure fell entirely on you.
The tools themselves reflected this philosophy. Obsidian's graph view was a revelation when it launched, but it only showed links you had manually created. Notion's databases were powerful, but they demanded upfront schema design. Roam's bidirectional linking reduced friction, but you still had to decide which blocks to connect. The user was the engine; the tool was the chassis.
That division of labor is now shifting. The engine is moving into the tool itself.
The 2026 Shift: From Manual Filing to Retrieval-and-Synthesis
The core change in 2026 is that AI now handles the structural heavy lifting — embeddings, semantic search, graph connections — while the user's job narrows to two things: capture quality and context curation. You no longer need to decide in advance whether a note belongs under "Project Alpha" or "Machine Learning Research." The system figures out the relationship later, when you ask a question.
This is not the same as the "AI will organize everything for you" promise that circulated in 2023 and 2024. That vision was premature. What changed is the maturity of three specific technologies — GraphRAG, MCP, and knowledge graphs — that together make retrieval-and-synthesis practical for real knowledge work. The user still curates. The user still decides what to capture. But the user no longer needs to pre-structure every note for future retrieval.
Key Technologies Driving the Shift: GraphRAG, MCP, and Knowledge Graphs
Three technologies form the backbone of AI-native PKM in 2026. Understanding how they differ — and how they work together — is essential for anyone evaluating a modern knowledge management system.
GraphRAG vs. Basic Vector RAG
Basic RAG (Retrieval-Augmented Generation) works by converting your notes into vector embeddings, then finding the most semantically similar chunks when you ask a question. It is a significant improvement over keyword search, but it has a blind spot: it treats each chunk as an isolated island. It does not understand that Note A (about transformer architecture) and Note B (about attention mechanisms) are related, even if they sit in different folders.
GraphRAG adds a knowledge graph layer on top of the vector index. It maps entities, concepts, and relationships across your entire knowledge base. When you ask a question, GraphRAG retrieves not just the most similar chunks, but also the surrounding context — the notes those chunks link to, the concepts they share, the hierarchy they belong to. The result is reasoning-driven retrieval rather than pure similarity matching.
| Capability | Basic Vector RAG | GraphRAG |
|---|---|---|
| Retrieval method | Semantic similarity only | Semantic similarity + graph traversal |
| Context awareness | Isolated chunks | Surrounding entities and relationships |
| Connection discovery | None — user must pre-link | Automatic — surfaces structural gaps |
| Query handling | Best for factoid questions | Better for multi-step reasoning |
| Data preparation | Embeddings only | Embeddings + entity extraction + graph construction |
The practical difference is visible when you ask a question like "What have I learned about attention mechanisms that applies to my current project?" Basic RAG returns the most similar paragraphs. GraphRAG returns those paragraphs plus the project notes they relate to, the papers you cited, and the meeting notes where you discussed implementation tradeoffs.
MCP: The Protocol That Connects LLMs to Your Knowledge Base
The Model Context Protocol (MCP) is the infrastructure standard that makes GraphRAG practical for everyday use. Before MCP, connecting an LLM to your PKM required custom API integrations, web scraping, or manual copy-pasting. MCP standardizes the connection: any MCP-compatible client — Claude, Cursor, ChatGPT — can query a knowledge graph endpoint directly, with citations back to the original notes.
This is not a theoretical capability. As of Q2 2026, tools like InfraNodus already support connecting any MCP-compatible client to a knowledge graph endpoint for cited Q&A. The user opens their AI assistant, asks a question, and receives an answer that includes references to specific notes in their PKM. The AI does not hallucinate because it is grounded in the user's own curated content.
Knowledge Graphs and Structural Gap Detection
A knowledge graph is more than a fancy tag system. It maps entities (people, concepts, projects, papers) and the relationships between them. Once this graph exists, the system can do something no folder hierarchy can: detect structural gaps.
InfraNodus's documentation describes structural gaps as pairs of clusters that are large but barely connected. In practice, this means your PKM might have a rich cluster of notes about reinforcement learning and another rich cluster about product design, with almost no links between them. A graph-based system surfaces this gap and asks: should these be connected? That question alone can spark insights that a folder-based system would never reveal.
Market Context: Why This Shift Matters Now
The technology shift is happening inside a rapidly growing market. The global knowledge management software market was valued at $23.2 billion in 2025 and is projected to reach $74.22 billion by 2034, growing at a compound annual growth rate of 13.8%, according to Fortune Business Insights data cited in industry analyses. This is not a niche category anymore.
The urgency is driven by a measurable productivity problem. McKinsey research indicates that knowledge workers spend an average of 9.3 hours per week searching for information — nearly a quarter of the workweek. Enterprise search systems achieve only a 10% first-attempt success rate, compared to Google's 95%, according to data from Glean. The gap between what we have saved and what we can retrieve is enormous.
- 41% of KM teams report that implementing AI is their top priority (APQC 2025 survey).
- 44% of KM experts rank generative AI as the most important emerging technology (APQC 2025 survey).
- Strong KM systems can reduce search time by up to 35% and boost organizational productivity by 20-25% (McKinsey).
- IDC data shows knowledge workers spend approximately 2.5 hours per day on information retrieval alone.
These numbers explain why PKM tool vendors are racing to integrate AI features. The demand is real, and the productivity upside is large enough to justify significant investment. But the market is also littered with failures — which brings us to the most important argument in this article.
How Tools Are Evolving: From Obsidian to InfraNodus to Heptabase
The technology shift is visible across the PKM tool landscape, though each tool approaches it differently. Understanding how specific tools implement GraphRAG, MCP, and knowledge graphs helps ground the abstract concepts in real workflows.
| Tool | AI Approach | Key Technology | User Impact |
|---|---|---|---|
| Obsidian | Plugin-driven AI ecosystem | 1,500+ community plugins | Users choose their AI stack; flexible but requires assembly |
| Notion AI | Integrated AI assistant | LLM-powered Q&A and writing | Seamless but limited to Notion's walled garden |
| InfraNodus | GraphRAG-native | MCP-compatible knowledge graph endpoint | Direct LLM querying of graph with citations |
| Tana | Supertag-based structure | AI-assisted tagging and linking | Reduces manual organization overhead |
| Heptabase | Visual knowledge graph | MCP integration for external AI tools | Combines visual thinking with AI retrieval |
Obsidian's plugin ecosystem — now exceeding 1,500 community plugins — means users can assemble their own AI stack by combining a local embedding plugin, a GraphRAG plugin, and an MCP bridge. This is powerful for technical users but requires significant setup effort. Notion AI, by contrast, offers a polished but walled-garden experience: the AI works within Notion's database structure but cannot reach into your local Markdown files or your Roam export.
InfraNodus and Heptabase represent the leading edge of GraphRAG-native design. InfraNodus's MCP-compatible knowledge graph endpoint is particularly notable: it allows any MCP-compatible client to query your graph directly, with citations. This is the closest current implementation to the vision of an AI that reads your entire knowledge base before answering.
The Truth Layer Trap: Why 95% of Enterprise AI Pilots Fail
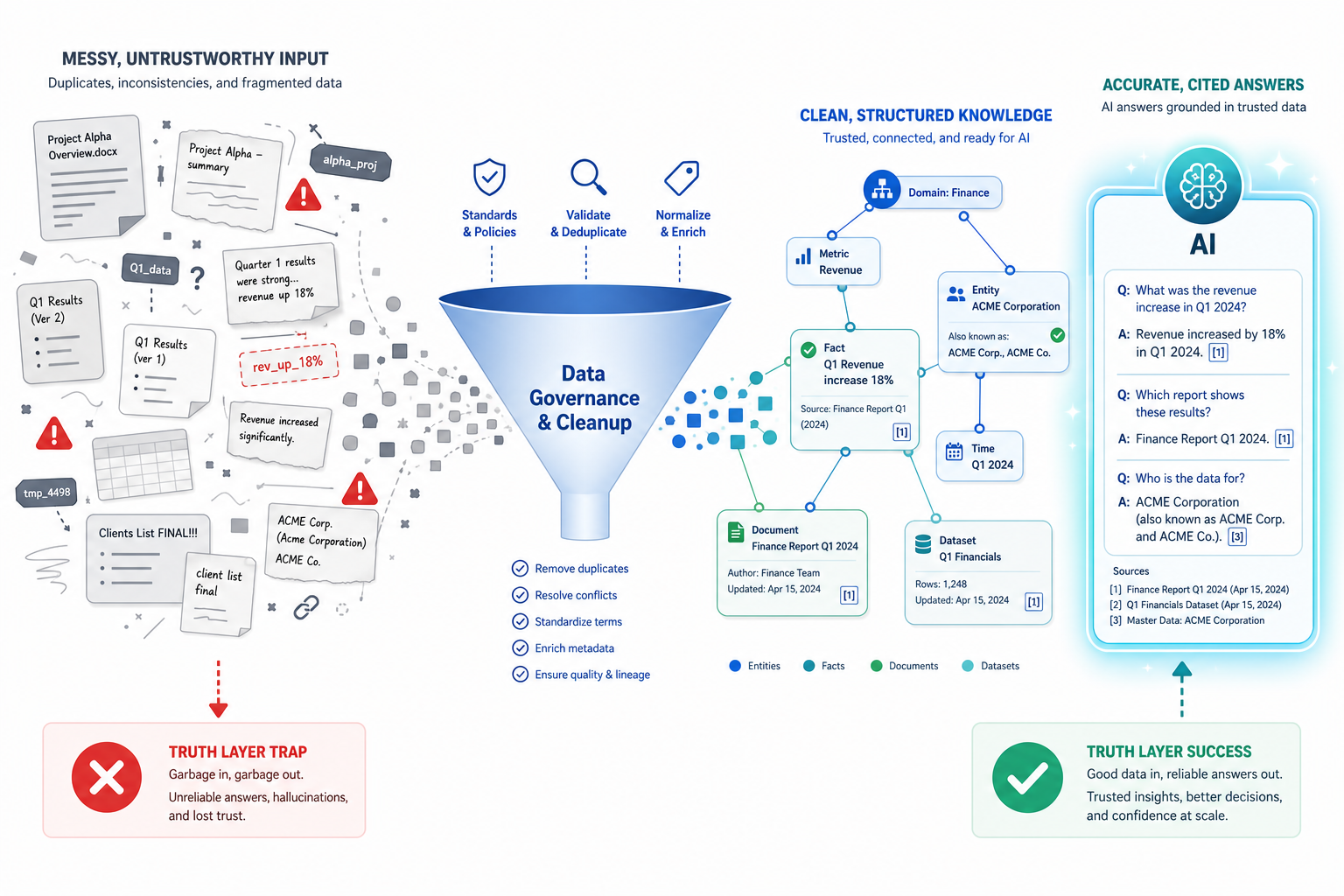
Here is the uncomfortable reality that every experienced PKM user needs to hear: 95% of enterprise AI pilots fail before delivering ROI, according to Full View research. The primary cause is not bad AI models. It is poor data integration and governance.
The same principle applies to personal knowledge management. GraphRAG, MCP, and agentic workflows are powerful, but they depend on a foundation of clean, connected, well-structured knowledge inputs. If your PKM is a dumping ground of unprocessed highlights, orphaned notes, and conflicting taxonomies, no amount of AI sophistication will produce reliable results. The AI will faithfully retrieve and synthesize your mess.
Industry analysts are already flagging this risk. Bloomfire's 2026 trend report emphasizes that funding the "truth layer" — content lifecycle management, deduplication, version controls, citation-backed answers — should come before funding the agent layer. Gartner predicts that 40% of AI agent deployments will fail by 2027 due to inadequate risk management and poor data integrity.
This is where the architecture decision between local-first and cloud PKM becomes critical. Local-first tools give you full control over your data and its structure, but they require you to manage backups, versioning, and deduplication yourself. Cloud tools handle infrastructure but may lock you into a proprietary data format that complicates migration. For a detailed breakdown of this tradeoff, see our guide on local-first vs. cloud PKM in 2026.
Practical Setup: Connecting Your PKM to AI via MCP
For experienced PKM users who want to experiment with AI-native retrieval today, the practical path involves three steps. This is not a full tutorial — tool interfaces change rapidly — but the high-level workflow is stable enough to guide your exploration.
- Choose a GraphRAG-capable PKM tool. InfraNodus and Heptabase are the most mature options as of Q2 2026. Both support MCP-compatible endpoints that allow external AI clients to query your knowledge graph.
- Set up your knowledge graph. Import your existing notes — the tool will extract entities and relationships automatically. Review the generated graph to verify that key concepts are correctly identified. This is where your curation effort matters: the graph is only as accurate as the notes it was built from.
- Connect an MCP-compatible AI client. Claude, Cursor, and ChatGPT all support MCP connections as of mid-2026. Configure the client to point to your knowledge graph endpoint. When you ask a question, the client queries the graph directly and returns answers with citations to specific notes in your PKM.
If you do not yet have a PKM tool and are evaluating options, the technology choices above will influence your decision. Our guide to choosing a PKM app in 2026 covers thinking styles, privacy considerations, and AI readiness — factors that matter more than feature checklists when selecting a system you will live in for years.
Outlook: Agentic Knowledge Management and the Future
The next frontier is agentic knowledge management, where the AI does not wait for you to ask questions. Instead, it monitors your knowledge base for structural gaps, surfacing connections you missed and flagging notes that contradict each other. It invokes you for approval rather than the reverse.
This is the vision behind "self-healing" knowledge bases — systems that detect orphaned notes, suggest merges for duplicates, and propose links between related concepts without manual intervention. Bloomfire's 2026 trend report identifies self-healing knowledge bases as one of the six defining trends of the year, alongside operationalized knowledge as strategic infrastructure and embedded intelligence.
But the Gartner prediction — that 40% of AI agent deployments will fail by 2027 due to poor data integrity — is a sobering counterweight. Agentic knowledge management will not work on a messy knowledge base. The agents will surface contradictions that do not exist, propose connections that are not meaningful, and generate confidence in unreliable information.
The PKM users who will benefit most from the 2026 shift are those who treat their knowledge base as a living system — reviewing it regularly, pruning dead notes, and maintaining the truth layer that makes AI retrieval reliable. The technology is ready. The question is whether your data is.
Comments
Join the discussion with an anonymous comment.